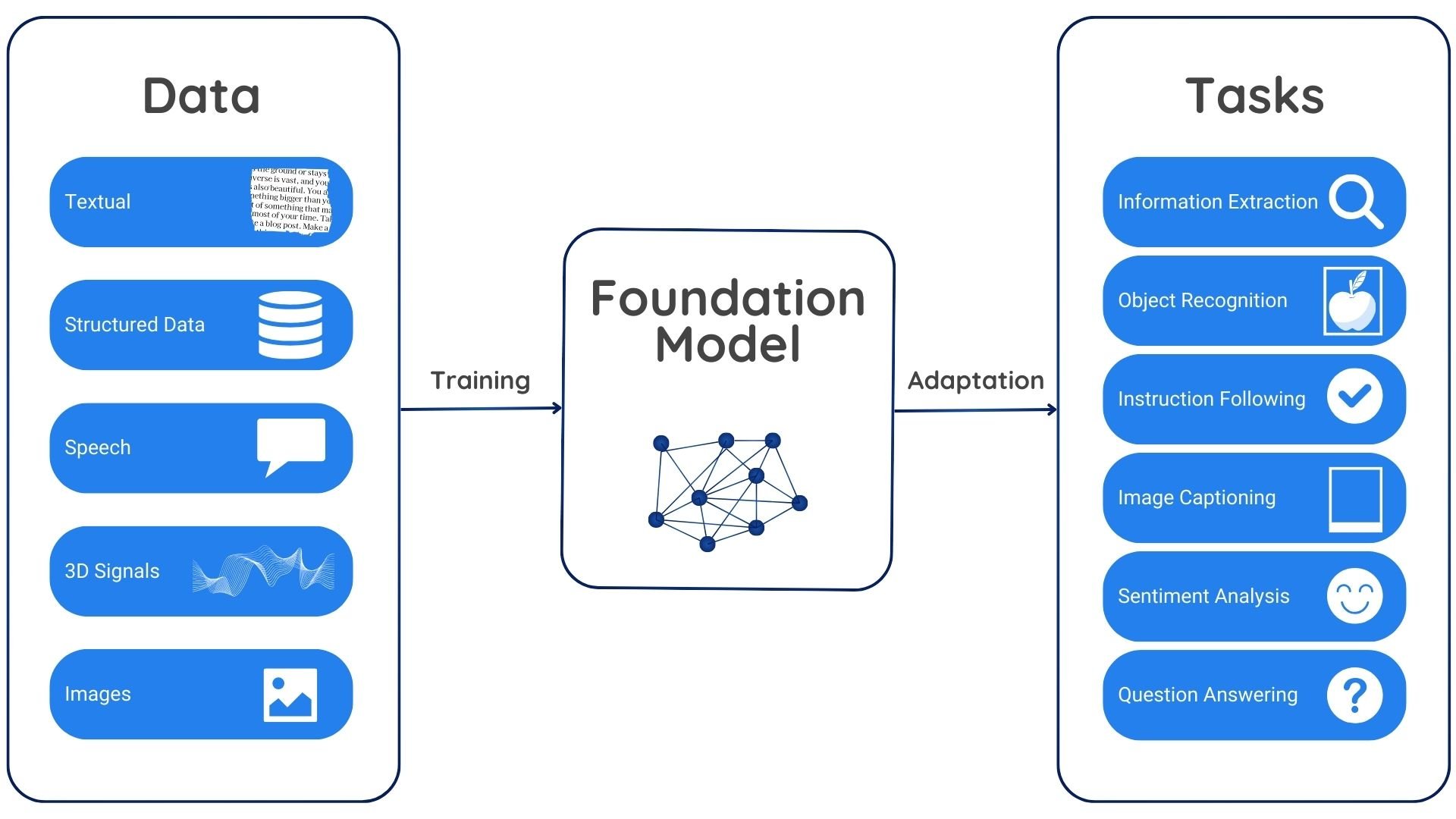
Let's be real for a second. Everyone and their cousin is currently trying to "build an AI app." You’ve seen the demos on X. You’ve seen the LinkedIn posts about how easy it is to wrap a prompt in a UI and call it a product. But if you’ve actually tried ai engineering: building applications with foundation models, you know the honeymoon phase ends the moment you hit a real-world edge case.
Building with foundation models is a weird, messy mix of traditional software engineering and something that feels more like alchemy. It’s not just about the code anymore. It’s about managing the inherent randomness of models like GPT-4, Claude 3.5, or Llama 3.
The Shift from Traditional Code to Probabilistic Systems
Standard software is predictable. You write an if statement, and provided your logic is sound, it does the same thing every single time. Foundation models don't work like that. They are probabilistic. You give the same prompt twice and might get two different answers. This is the first big hurdle in ai engineering: building applications with foundation models.
💡 You might also like: The Prius Power Mode: Why You’re Probably Using It Wrong
You're essentially trying to build a rigid bridge using materials that behave like liquid.
Swyx (Shawn Wang), who basically coined the term "AI Engineer," argues that this role is distinct from a Data Scientist. You aren't training the weights from scratch. You aren't doing calculus or managing GPU clusters most of the time. Instead, you're an orchestrator. You are taking these massive, pre-trained "black boxes" and trying to wire them into a system that actually solves a user's problem without hallucinating or costing $50 per query.
Prompt Engineering is Just a Band-Aid
Early on, we thought "Prompt Engineering" was the whole game. We spent weeks trying to find the perfect magic words to stop a model from lying. Honestly, it was a bit silly. While the way you frame a request matters, relying solely on prompting is a recipe for a fragile application.
Modern ai engineering: building applications with foundation models has moved toward more robust architectures. Specifically, we’re seeing a massive shift toward RAG (Retrieval-Augmented Generation) and Agentic workflows.
Why RAG Is Still King (But Also Hard)
RAG is basically giving the model an open-book exam. Instead of asking it to remember a fact from its training data, you search a private database, find the relevant text, and stuff it into the prompt. It works. It reduces hallucinations significantly. But the "engineering" part is where it gets sticky.
You have to worry about:
👉 See also: Internet Download Manager for MacBook: The Brutally Honest Truth
- Chunking strategies: How do you cut up your documents so they make sense?
- Embedding models: Which model are you using to turn text into math?
- Vector databases: Using Pinecone, Weaviate, or just pgvector?
- Re-ranking: The search might return 10 results, but only two are actually useful. How do you pick them?
If your RAG pipeline is bad, your foundation model will just confidently summarize the wrong information. It's "garbage in, garbage out" on steroids.
The Latency and Cost Trap
Here is something people rarely mention in those "build an AI startup in 24 hours" videos: foundation models are slow. And they are expensive.
If your application requires five consecutive LLM calls to finish a single task, and each call takes 3 seconds, your user is sitting there for 15 seconds staring at a loading spinner. That's a death sentence for UX. Part of ai engineering: building applications with foundation models is learning how to do "LLM cascading."
You use a small, cheap model (like GPT-4o-mini or Haiku) for the easy stuff. Then, you only call the big, expensive model (like Claude 3.5 Sonnet or GPT-4o) when you really need the "heavy lifting." This saves money and shaves seconds off the response time.
Evaluation is the Hardest Part
How do you know your app is actually getting better? In normal dev work, you write unit tests. In AI engineering, unit tests are notoriously difficult. You can't just check if the output equals "True."
You have to use "LLM-as-a-judge" or frameworks like RAGAS or Arize Phoenix. You basically have one AI model grading the homework of another AI model. It feels a bit like the "Inception" of software development, but it's currently the only way to scale testing without having humans read every single output.
Moving Toward Agentic Workflows
We are moving away from simple "Chatbot" interfaces. The real future of ai engineering: building applications with foundation models lies in agents. These are systems that can use tools.
Think about a model that doesn't just tell you the weather but can actually log into your email, find your flight itinerary, see that your flight is delayed, and then draft a message to your Uber driver.
This requires a loop:
- Reasoning: What should I do?
- Action: Use a tool (API call, database query).
- Observation: What did the tool return?
- Repeat: Do I need to do more?
It’s powerful, but it’s also a nightmare to debug. An agent can get stuck in an infinite loop or decide to delete a database if your "system prompt" isn't airtight. Security—specifically prompt injection—becomes a massive concern here. If a user can trick your agent into running a malicious command, your foundation model-based app becomes a liability.
Real-World Nuance: The "Vibe Check"
Despite all the tools and metrics, a huge part of building with these models still comes down to the "vibe check." You'll spend hours tweaking a temperature setting or a system instruction just because the output "felt" a bit too robotic.
It’s a different kind of expertise. You need the technical chops to build the infra, but also the linguistic intuition to guide the model. It's why many of the best AI engineers aren't just CS grads; they are people who understand how language and logic intersect.
Actionable Steps for Aspiring AI Engineers
If you want to move beyond the surface level, stop just calling APIs and start looking at the system as a whole.
- Master Data Prep: Your model is only as good as the context you give it. Spend time learning about metadata filtering in vector databases.
- Implement Tracing: Use tools like LangSmith or LangFuse from day one. If you can't see what's happening inside your chains, you can't fix them.
- Build an Eval Suite: Create a "Golden Dataset" of 50-100 questions and "ideal" answers. Every time you change your prompt or model, run it against this set to ensure you haven't regressed.
- Optimize for Latency: Use streaming (server-sent events) so the user sees text appearing immediately. It’s a psychological trick, but it makes the app feel 10x faster.
- Don't Over-Engineer: Sometimes a regex or a simple Python script is better than a foundation model. Don't use a billion-parameter model to do something a 10-line script can do.
The field is moving so fast that what works today might be obsolete by Tuesday. But the core principles of ai engineering: building applications with foundation models—managing uncertainty, optimizing context, and rigorous evaluation—aren't going anywhere. Focus on the architecture, not just the model name.